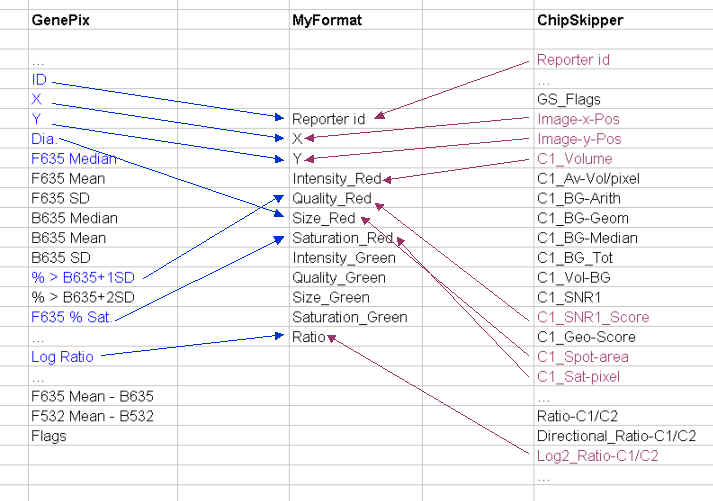
The example shows how to select somewhat corresponding data columns and how to reorder them. The aim would be to create a homogenous file structure for subsequent filtering.
This function allows to reduce the number and the order of columns in data files.
We use this function mainly for two purposes :
The example shows how to select somewhat corresponding data columns and how to
reorder them. The aim would be to create a homogenous file structure for
subsequent filtering.
2. Create reduced data files for publication. Not all data columns are useful for being submitted to microarray databases like ArrayExpress (e.g. image coordinates of the spots, when image files are not available from EBI).
TableButler shows a preview of the Source and the Rearranged files :
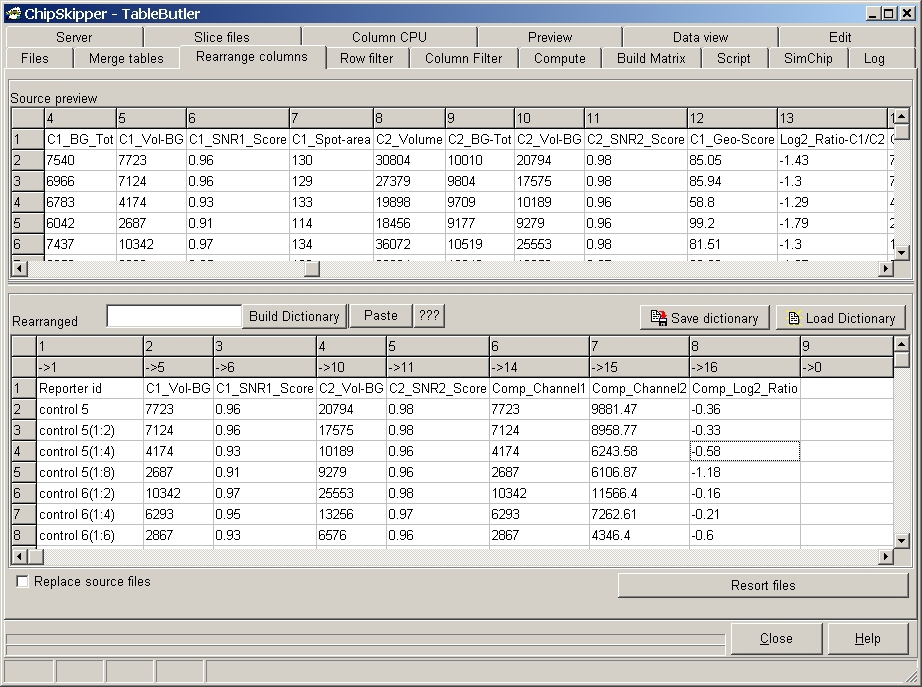
Double-click the desired columns in the Source-Preview grid.
They will be automatically appended in the Rearranged grid. The already selected
columns are shown with light gray background:
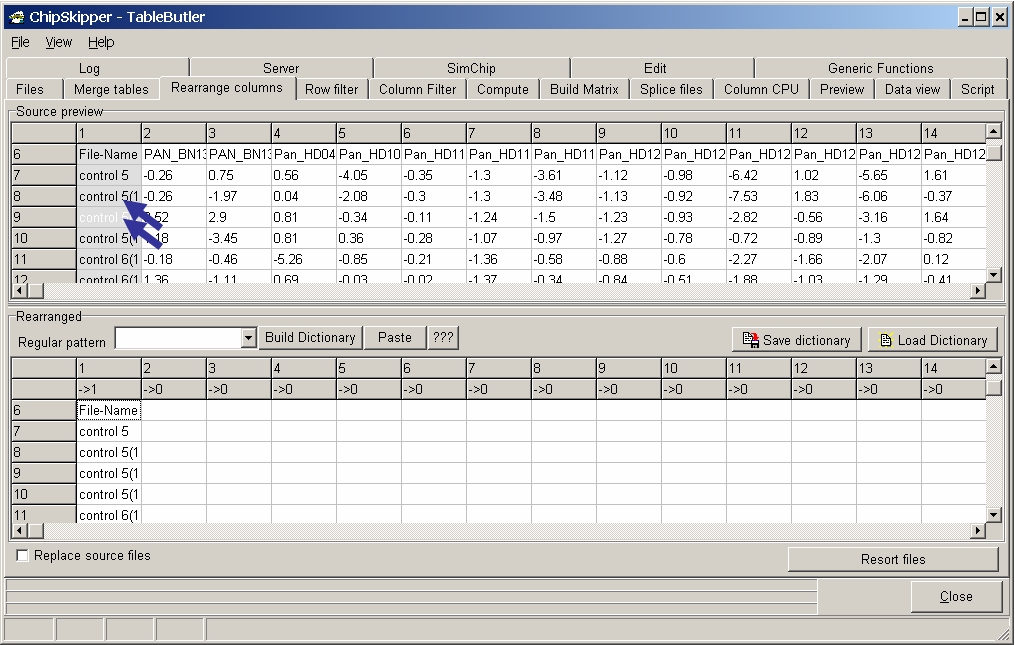
Double-click the next column in Source preview
to add it to the rearranged file:
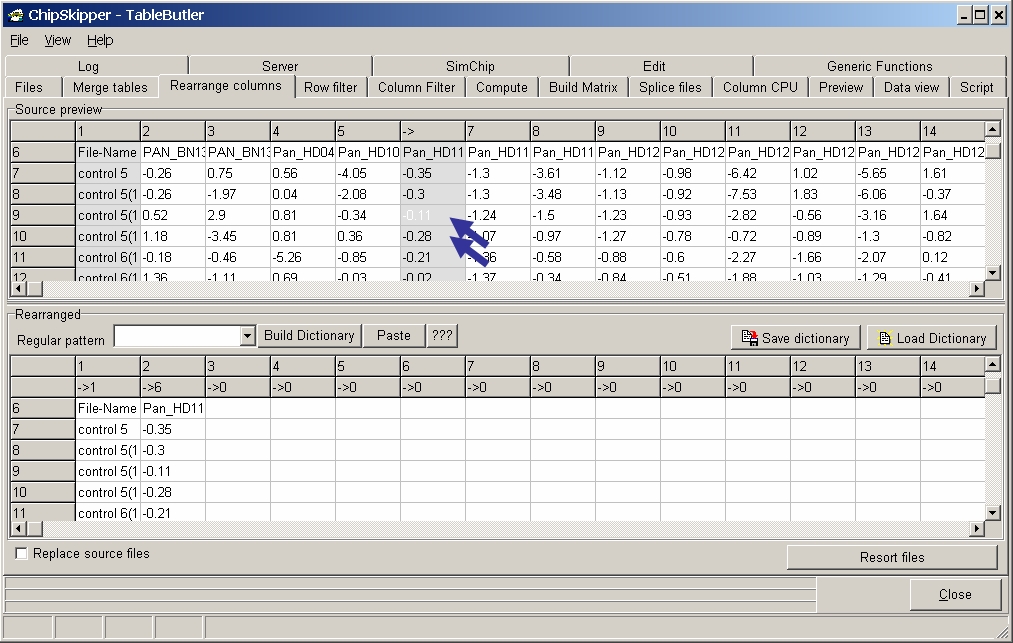
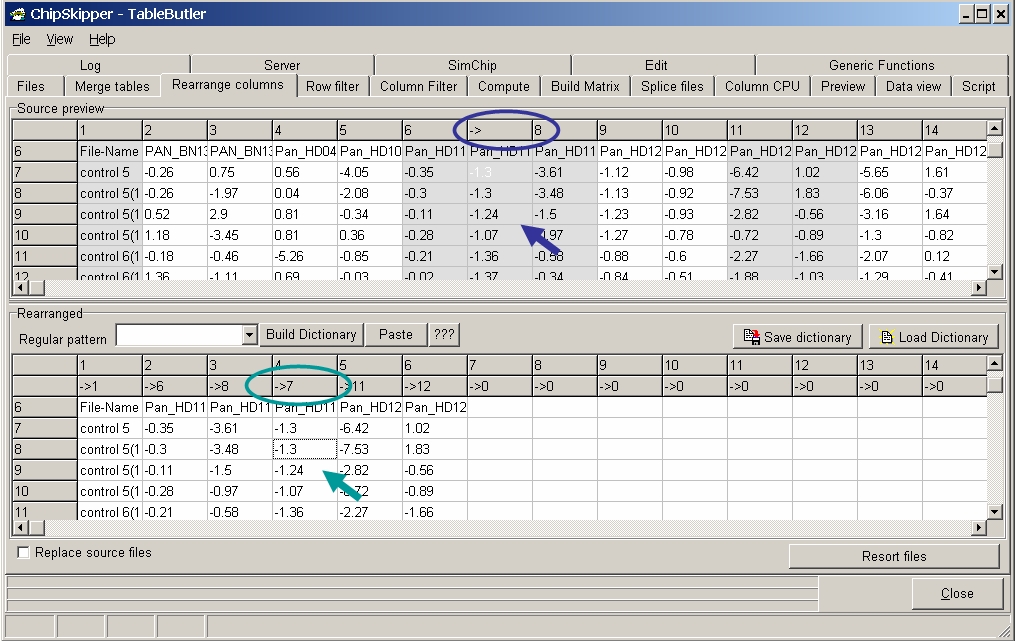
Click a data column in the Source grid then the corresponding colum in the Rearranged grid to assign the columns in the target files. The preview of the Rearranged grid is immediately updated:
Click the Rearranged subgrid with right mouse button:
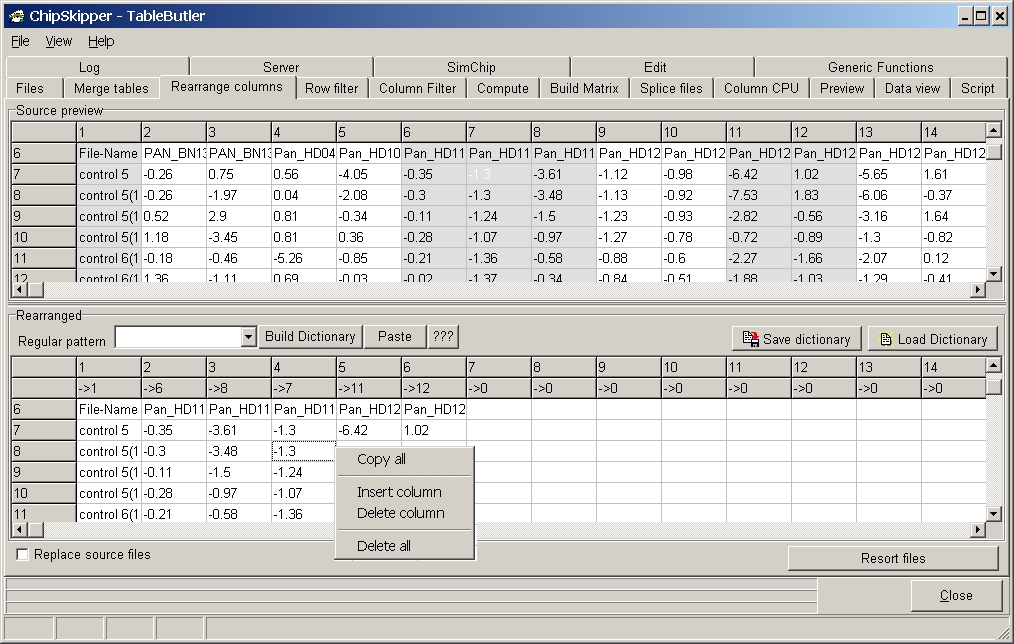
From the context-menu you can select:
Type a simple regular range expression into the
Regular pattern edit field.
E.g. "5..10" will add columns 5 to 10 at presently selected columnin the
Rearranged grid.
When large regular data files (e.g. public downloadable expression data)
shall be rearranged, a regular expression syntax may be used to resort data
columns.
Type in the Regular pattern edit field a regular expression and click the Build Dictionary
button. A regular expression looks like:
[Start Column]:[Columns]:[Offset]:[Repetitions]
e.g. 3:0,2,5..8,12:20:3
means:
Click Replace Source files to overwrite the source data files.
Assume we would like to resort the columns from the example shanpshot into order:
C1_Vol-BG, C2_Vol-BG, Reporter_ID
You can do this by placing into the Regular pattern field:
byname:contains:: C1_Vol-BG C2_Vol-BG Reporter_ID
| "byname" | tells TableButler you supply a list of column headers (and not a numerical regular expression) |
| ":contains" | tells TableButler to look for partial
occurence of the search value. This is optional. e.g. "byname:contains:: Rep Vol-BG" would be more easy selection for Reporter_ID column BUT ambiguously select the first ocurrence of column containing Vol-BG - be careful. |
| ":: " | tells TableButler from now on starts the Header list. |
| "C1_Vol-BG C2_Vol-BG Reporter_ID" |
If you generate the name list with a data base query in e.g. Access or Excel, the copied list may contains Tabs or Line feed characters which are not nicely accepted in a combo-box. To paste such expression click the Paste-Button. TableButlers takes the clipbord content and removes such characters.
In the example we show selection of 8 the most significant columns for subsequent filtering and clustering out of the 58 columns offered by ChipSkipper :
Comment = GeneID we can link up with our annotation database
C1-Vol-BG = Total background reduced intensity of the spot in Red
color channel
C1_%SNR = Intensity score for the spot in Red color channel
C2-Vol-BG = Total background reduced intensity of the spot in Green color
channel
C2_%SNR = Intensity score for the spot in Green color channel
Comp_Channel1 = Normalized intensity for spot in Red color channel
Comp_Channel2 = Normalized intensity for spot in Green color channel
Comp_Ratio = Normalized Ratio (log2)
Such a "translation" schema may be saved as a Dictionary for later use.
Last edited 02.03.2006,